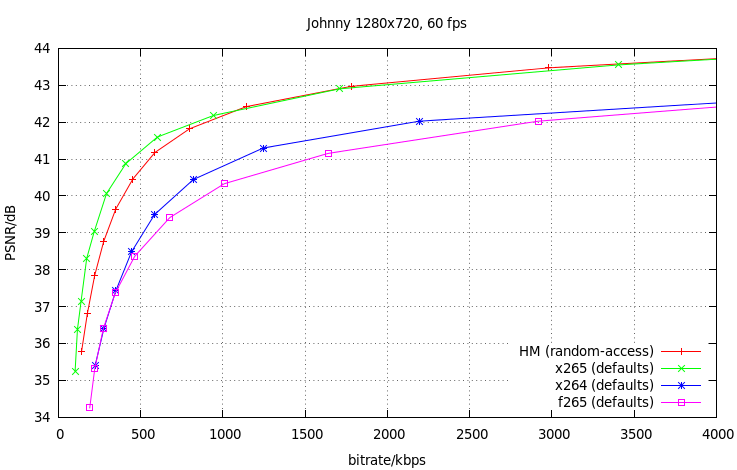
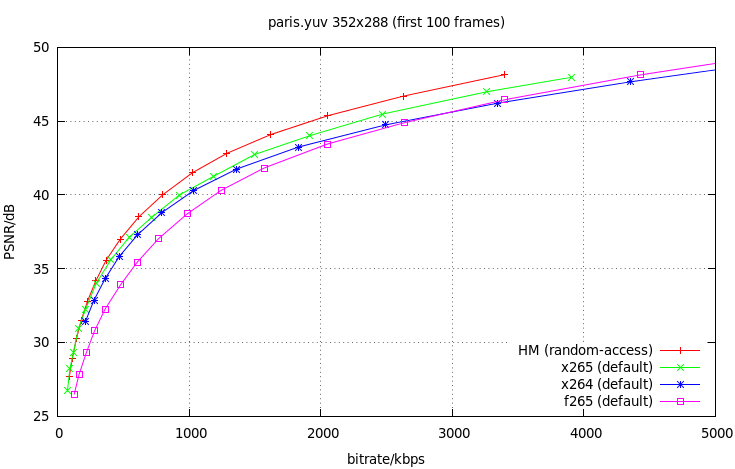
Preface of PCR, PTS/DTS & Time Base Alterations according to ISO/IEC 13818 Part 1, Annexure D, JGiven that a decoding system receives a compliant bit stream that is delivered correctly in accordance with the timing model it is straightforward to implement the decoder such that it produces as output high quality audio and video which are properly synchronized. There is no normative requirement, however, that decoders be implemented in such a way as to provide such high quality presentation output. In applications where the data are not delivered to the decoder with correct timing, it may be possible to produce the desired presentation output; however such capabilities are not in general guaranteed.

The audio and video sample rates at the encoder are significantly different from one another, and may or may not have an exact and fixed relationship to one another, depending on whether the combined stream is a Program Stream or a Transport Stream, and on whether the System_audio_locked and System_video_locked flags are set in the Program Stream. The duration of a block of audio samples (an audio presentation unit) is generally not the same as the duration of a video picture.
[Within the coding of this Recommendation, data are timestamps concerning the presentation and decoding of video pictures and blocks of audio samples. The pictures and blocks are called "Presentation Units", abbreviated PU. The sets of coded bits which represent the PUs and which are included within the ISO/IEC 13818-1 bit stream are called "Access Units", abbreviated AU. An audio access unit is abbreviated AAU, and a video access unit is abbreviated VAU. In ISO/IEC 13818-3, the term "audio frame" has the same meaning as AAU or APU (audio presentation unit) depending on the context. A video presentation unit (VPU) is a picture, and a VAU is a coded picture.]
Some, but not necessarily all, AAUs and VAUs have associated with them PTSs. A PTS indicates the time that the PU which results from decoding the AU which is associated with the PTS should be presented to the user. The audio PTSs and video PTSs are both samples from a common time clock, which is referred to as the System Time Clock or STC. With the correct values of audio and video PTSs included in the data stream, and with the presentation of the audio and video PUs occurring at the time indicated by the appropriate PTSs in terms of the common STC, precise synchronization of the presented audio and video is achieved at the decoding system. While the STC is not part of the normative content of this Recommendation, and the equivalent information is conveyed in this Recommendation via such terms as the system_clock_frequency, the STC is an important and convenient element for explaining the timing model, and it is generally practical to implement encoders and decoders which include an STC in some form.
[In particular, in the STD model each of the operations performed on the bit stream in the decoder is performed instantaneously, with the obvious exception of the time that bits spend in the decoder buffers. In a real decoder system the individual audio and video decoders do not perform instantaneously, and their delays must be taken into account in the design of the implementation. For example, if video pictures are decoded in exactly one picture presentation interval 1/P, where P is the frame rate, and compressed video data are arriving at the decoder at bit rate R, the completion of removing
bits associated with each picture is delayed from the time indicated in the PTS and DTS fields by 1/P, and the video decoder buffer must be larger than that specified in the STD model by R/P. The video presentation is likewise delayed with respect to the STD, and the PTS should be handled accordingly. Since the video is delayed, the audio decoding and presentation should be delayed by a similar amount in order to provide correct synchronization. Delaying decoding and presentation of audio and video in a decoder may be implemented for example by adding a constant to the PTS values when they are used within the decoder.]
Data from the Transport Stream enters the decoder at a piecewise constant rate. The time t(i) at which the i-th byte enters the decoder is defined by decoding the program clock reference (PCR) fields in the input stream, encoded in the Transport
Stream packet adaptation field of the program to be decoded and by counting the bytes in the complete Transport Stream between successive PCRs of that program. The PCR field is encoded in two parts: one, in units of the period of 1/300 times the system clock frequency, called program_clock_reference_base, and one in units of the system clock frequency called program_clock_reference_extension. The values encoded in these are computed by PCR_base(i) and PCR_ext(i) respectively. The value encoded in the PCR field indicates the time t(i), where i is the index of the byte containing the last bit of the program_clock_reference_base field.
Specifically:
PCR(i) = PCR_base(i) × 300 + PCR_ext(i)
where: PCR_base(i) = ((system_clock_ frequency × t(i)) DIV 300) % 233, and,
PCR_ext(i) = ((system_clock_ frequency × t(i)) DIV 1) % 300
For all other bytes the input arrival time, t(i) shown in equation below, is computed from PCR( i'') and the transportrate at which data arrive, where the transport rate is determined as the number of bytes in the Transport Stream between the bytes containing the last bit of two successive program_clock_reference_base fields of the same program divided by the difference between the time values encoded in these same two PCR fields.
t(i) = PCR(i'')/system_clock_ frequency +( i − i'')/transport_rate (i)
where,
i is the index of any byte in the Transport Stream for i''< i < i'
i'' is the index of the byte containing the last bit of the most recent program_clock_reference_base field applicable to the program being decoded. PCR(i'') is the time encoded in the program clock reference base and extension fields in units of the system clock.
The transport rate is given by,
transport_rate(i) = ((i' – i'' ) × system_clock_frequency)/ PCR(i') – PCR(i'')
where,
i'is the index of the byte containing the last bit of the immediately following program_clock_reference_base field applicable to the program being decoded, such that, i'' < i ≤ i'
In the case of a time base discontinuity, indicated by the discontinuity_indicator in the transport packet adaptation field, the definition for the time of arrival of bytes at the input to the decoder is not applicable between the last PCR of the old time base and the first PCR of the new time base. In this case the time of arrival of these bytes is determined according to equation to Evaluate t(i) above with the modification that the transport rate used is that applicable between the last and next to last PCR of the old time base.
A tolerance is specified for the PCR values. The PCR tolerance is defined as the maximum inaccuracy allowed in received PCRs. This inaccuracy may be due to imprecision in the PCR values or to PCR modification during re-multiplexing. It does not include errors in packet arrival time due to network jitter or other causes. The PCR tolerance is ± 500 ns.
Transport Streams with multiple programs and variable rate
Transport Streams may contain multiple programs which have independent time bases. Separate sets of PCRs, as indicated by the respective PCR_PID values, are required for each such independent program, and therefore the PCRs cannot be co-located. The Transport Stream rate is piecewise constant for the program entering the T-STD. Therefore, if the Transport Stream rate is variable it can only vary at the PCRs of the program under consideration. Since the PCRs, and therefore the points in the transport Stream where the rate varies, are not co-located, the rate at which the Transport Stream enters the T-STD would have to differ depending on which program is entering the T-STD. Therefore, it is not possible to construct a consistent T-STD delivery schedule for an entire Transport Stream when that Transport Stream contains multiple programs with independent time bases and the rate of the Transport Stream is variable. It is straightforward, however, to construct constant bit rate Transport Streams with multiple variable rate programs.
The following schematic represents the Broadcom BCM97405’s Time Stamp Management, which roughly constitutes of the following:-
1. A single software point of control. This is called the “global STC.” All other implementation details should be as transparent as possible to software (usage of PVR offset, PCR offset, STC, etc.) This implies that the STC for audio and video decoders should match exactly.
2. Audio and video must be synchronized in time. The basic specification is to allow up to ± 20 ms of audiovisual disparity.
3. Audio and video decoders must present the same TSM interface and behave consistently. This means, for example, that if one decoder drops frames prior to receiving an initial STC in Broadcast mode, the other decoder should also do so. Similarly, if one decoder enters VSYNC mode during the same time period, then the other decoder should also.
4. Error concealment must be implemented. This means that the decoder and transport software/firmware/hardware should attempt to conceal errors in a way that meets all relevant compliance testing and in such a way that host/system software involvement is minimized.
5. VSYNC mode time must be minimized. This means that when time stamp management information is available, we should use it.
6. Audio PLLs must be locked to incoming streams and VCXOs/VECs.
The decoder uses time stamps provided in the stream to control when a frame must be displayed (PTS) or decoded (DTS). These time stamps are compared to a running system clock – the STC. Because the decoder cannot always display or decode a frame exactly when the STC and PTS are equal, a small amount of latitude is given to the decoder. This latitude translates into a threshold, within which the decoder will take one action on a frame, and beyond which the decoder will take a different action.
Generally, the time line for timestamp comparisons is divided into four sections:
• Extremely early
• Early
• Late
• Extremely late.
The dividers between these sections are the “threshold” values that determine what constitutes, for example, “extremely late” vs. “late”. In a line with four sections, there must be three such dividers: the extremely early threshold, the extremely late threshold, and the point at which a frame is exactly on time, called the maturation point (PTS = STC). Each decoder may have different early or late thresholds as best suits the performance requirements for a given usage mode for that decoder. The following scenarios apply to both the broadcast and PVR usage modes. Extremely Early Frames (PTS > STC + Threshold) extremely early frames put a burden on the buffer model of the decoder. If they are not discarded, the buffer may overflow. The threshold value for determining whether a frame is simply early or extremely early is a function of the available buffer size to which the decoder has access. An extremely early frame will be discarded and the host will be notified of a PTS error. The decoder should not expect the host to correct the problem. This is depicted in the Figure below.

Early Frames (STC + Threshold > PTS > STC) Early frames should be presented/decoded when their PTS matures. No host or transport interaction is required. This is depicted in the Figure below.
Punctual Frames (PTS = STC) Punctual frames are those that arrive at the TSM module at the maturation point. These should be presented/decoded immediately. No host or transport interaction is required. This is depicted in the Figure below.
Late Frames (STC > PTS > STC – Threshold) Late frames should be presented/decoded immediately. No host or transport interaction is required. This is depicted in the Figure below.
Extremely Late Frames (STC – Threshold > PTS) Extremely late frames should also be discarded. In the absence of another frame/sample, the last frame/sample should be presented. The decoder should generate a PTS error to the host signifying the problem, but should not require any host interaction to correct the situation. This is depicted in the Figure below.
In addition, there is a real-time interface specification for input of Transport Streams and Program Streams to a decoder. This allows the standardization of the interface between MPEG decoders and adapters to networks, channels, or storage media. The timing effects of channels, and the inability of practical adapters to eliminate completely these effects, causes deviations from the idealized byte delivery schedule to occur. This covers the
real-time delivery behavior of Transport Streams and Program streams to decoders, such that the coded data buffers in decoders are guaranteed neither to overflow nor underflow, and decoders are guaranteed to be able to perform clock recovery with the performance required by their applications.
The MPEG real-time interface specifies the maximum allowable amount of deviation from the idealized byte delivery schedule which is indicated by the Program Clock Reference (PCR) and System Clock Reference (SCR) fields encoded in the stream. Implementations of the process for recording and playback conform to the following sections. Please note that this is not complete. Please refer to ETSI TS 102 819 and ETSI ES 201 812 for completeness.
For systems implementing the MHP Stack, the process for Managing scheduled recordings includes the following activities:
1. Maintaining a list of recording requests which remain in the pending state (PENDING_WITH_CONFLICT_STATE or PENDING_WITHOUT_CONFLICT_STATE).
2. Maintaining a list of recording requests that have been successfully completed (COMPLETED_STATE), ones where recording started but failed to be successfully completed (INCOMPLETE_STATE) and ones where recording was scheduled but failed to start (FAILED_STATE).
3. Initiating the recording process for a pending recording request (in either PENDING_WITH_CONFLICT_STATE or PENDING_WITHOUT_CONFLICT_STATE) at the appropriate time, including awakening from a standby or similar power management state should this be necessary.
4. Maintaining references to recording requests that failed (FAILED_STATE) in the list of recording requests.
5. Resolving ParentRecordingRequests, initially when the request is first made and at subsequent times depending on the GEM recording specification. This includes setting the initial state of the ParentRecordingRequest and changing that state when or if more of the request is resolved.
Notes:- GEM recording specifications may define mechanisms for automatically removing requests from this list if it appears the recording will never happen. GEM recording specifications may define mechanisms for automatically removing requests from this list based on some criteria they define. Mechanisms for resolving conflicts between recording requests (e.g. use of the tuner) are outside the scope of the present document and may be specified by GEM recording specifications. The GEM recording specification is responsible for specifying the mechanism for resolving ParentRecordingRequests.
The recording process includes the following activities:
1. Identifying which recordable streams shall be recorded. If the specification of the recording request identifies specific streams then those are the ones which shall be recorded. If the specification of the recording request does not identify specific streams then the default streams in the piece of content shall be recorded. When the recording is in progress and an elementary stream is added to or removed from the program, the device shall re-evaluate the streams to record as if the recording were just starting. If during this process the device determines that different streams need to be recorded it should change the streams being recorded without segmenting the recording if possible. If the device cannot change streams being recorded without segmenting the recording then it shall segment the recording.
2. Recording the identified streams, up to the limits in the recording capability of the GEM recording terminal.
Where more streams of any one type should be recorded than the GEM recording terminal can record, streams shall be prioritized
3. Identifying recordable applications and recording them, the broadcast file system(s) carrying them and sufficient data to reconstruct their AIT entries. Applications with an Application recording description where the scheduled_recording_flag is set to "0" shall not be considered as recordable. On implementations which monitor for changes in the application signaling, when such changes be detected then the criteria for which applications are recordable shall be re-evaluated. If any applications which were recordable becomes non-recordable or vice-versa then this shall be acted upon.
4. Recording sufficient information about all transmitted timelines which form part of the recording in order to enable them to be accurately reconstructed during playback.
5. Generating a media time which increments linearly at a rate of 1,0 from the beginning to the end of the recording.
6. Recording sufficient SI to identify the language associated with those recordable streams (e.g. audio) that can be specified by language - e.g. using org.davic.media.AudioLanguageControl "what SI should be recorded with a recorded service, e.g. info about languages?" added above requirement.
7. Handling the following cases relating to the loss and re-acquisition of resources during a recording:
- the recording starts and a needed resource is not available;
- the recording is in progress and a needed resource is lost;
- the recording is in progress without a needed resource and the resource becomes available.
8. Handling the following cases relating to changes to elementary stream information during a recording:
- an elementary stream with audio, video, or data is added;
- an elementary stream with audio, video, or data is removed;
- an elementary stream with audio, video, or data is changed, e.g. the PID changed.
Notes:- The definition of the default streams to be recorded is outside the scope of the present document and should be specified by GEM recording specifications. Minimum capabilities for the number of streams of each type that GEM recording terminals should be able to record are outside the scope of the present document. The GEM recording specification is responsible for defining these. A more complete definition of which applications are recordable (and which are not) is outside the scope of the present document and should be specified by GEM recording specifications. The requirements on a GEM recording terminal to monitor for dynamic data and behavior of applications during a recording are outside the scope of the present document and should be specified by GEM recording specifications.
Managing completed recordings
The process for managing completed recordings shall include the following activities: Maintaining with all completed recordings (COMPLETED_STATE or INCOMPLETE_STATE) the following information as long as the content is retained:
- whether the recording is known to be complete or incomplete or whether this is unknown;
- whether the recording is segmented and information about each segment;
- the time and channel where the recording was made;
- the application specific data associated with the recording.
Possibly deleting the recording (including the entry in the list of recordings, the recorded data and any other associated information) once the expiration period is past for the leaf recording request corresponding to this recording.
NOTE: The present document is silent about the precision with which the expiration period must be respected. GEM recording specifications should specify how accurately it should be enforced by implementations.
Playback of scheduled recordings
Except when the initiating_replay_flag in the Application recording description of any application in the recording is set to "1", the process for playing back scheduled recordings shall include the following activities:
1) Starting the playback of recordable streams;
2) Starting the playback of recorded AUTOSTART applications where these form part of the recorded piece of content and all labeled parts of the application with the storage priority "critical to store" have been stored. Requirements on reconstructing the dynamic behavior of recorded applications during playback are outside the scope of the present document and should be specified by GEM recording specifications. When playing content which is currently being recorded, if the end of the content to be recorded is reached and recording stops, the playback must continue without interruption (but not necessarily perfectly seamlessly), regardless of any (implementation dependent) process to copy the newly recorded content from any temporary buffer to a more permanent location on the storage device.
3) A time shall be synthesized which increases linearly from the start of the recorded content to the end. This shall be used as the basis of the "time base time" and "media time" as defined by JMF. No relationship is required between this time and any time that forms part of the recorded content such as MPEG PCR, STC or DSMCC NPT.
4) When playing an entire recording with multiple segments, the segments shall be treated as a single recording. The segments shall be played in the order they appear in the array returned from the SegmentedRecordedService.getSegments method, and a time shall be synthesized for all of the segments as described in rule number 4 above. When playing across a gap between two segments the (implementation dependent) time of the gap should be minimized as much as possible with 0 gap time the goal.
5) When playing a single segment from a recording that includes multiple segments the single segment shall be treated as an entire recording playback. The beginning and end of the segment shall be the beginning and end of the playback.
6) For all transmitted time lines which form part of the original recording, reconstruct each time line when the current media time is in the range for which that time line is valid. Applications where labeled parts of the application with the storage property "critical to store" have not been stored shall be treated as if none of the application has been stored. They shall not appear to be present. When the initiating_replay_flag in the Application recording description of any application in the recording is set to "1", the GEM recording terminal shall launch the first auto-start application in the recording which has initiating_replay_flag set to "1". The GEM recording terminal shall not initiate the playback of the recordable streams since this is the responsibility of that application.
*******This paper is IEEE paper and no modifications done from me************